Can LLMs Play Catan?
Chess and Go have been the standard tests of machine game-playing for decades, but they're also clean, sterile problems. The strategic reasoning most of us do at work every day looks nothing like that.
If you believe LLM agents are going to negotiate contracts, manage supply chains, or broker deals on our behalf, you probably want to know how they handle a situation where four parties with competing interests have to trade, plan under uncertainty, and adapt to each other in real time. Settlers of Catan is a pretty good proxy. It's the kind of messy, multi-stakeholder problem that frontier LLMs should theoretically be good at, and the kind that's hard to benchmark with multiple choice questions.
So I sat four LLMs down at a Catan table: Claude Sonnet 4.5, Claude Haiku 4.5, Gemini 2.5 Flash, and Gemini 3 Flash Preview. No fine-tuning, no MCTS, and no RL. Just a text prompt describing the board, the rules, and a numbered list of legal moves. They pick one, explain why, and jot notes to themselves for next turn. I made them play forty-eight games, spanning about 13,000 API calls and spending $25 in API calls.
How It Works
Each game runs on Catanatron, an open-source Catan engine that handles the rules, dice, and resource distribution. The models never touch the engine directly. They just see a text snapshot of the game state and choose from a list of legal actions by index.
The system prompt gives them the full rules of Catan. Building costs, dice probabilities, how the robber works, what each development card does, how victory points are counted. The goal here to test strategic reasoning, not if the model has memorized the rulebook from its training data.
Each turn, a model sees:
- The board state: who's built what, where the robber is, VP counts
- Their own hand (opponents' hands are hidden, like real Catan; they only see card totals)
- The last 8 game events: dice rolls, builds, trades
- Their scratchpad notes from the previous turn
- A numbered list of legal actions
They respond with a JSON: an action index, a brief explanation, and updated scratchpad notes. The scratchpad is the closest thing they have to memory between turns, a 2000-character notepad that persists across the game. Models use it to track plans, count VP, and (sometimes) to write the same sentence 69 times in a row. This is intended to keep track of high-level strategy and trends in working memory, like human players.
I also bolted on domestic trading. After each dice roll, the active player can propose a 1-for-1 trade to any opponent. The target independently accepts or rejects. This is the one piece of genuine multi-agent negotiation in the setup.
What I Found
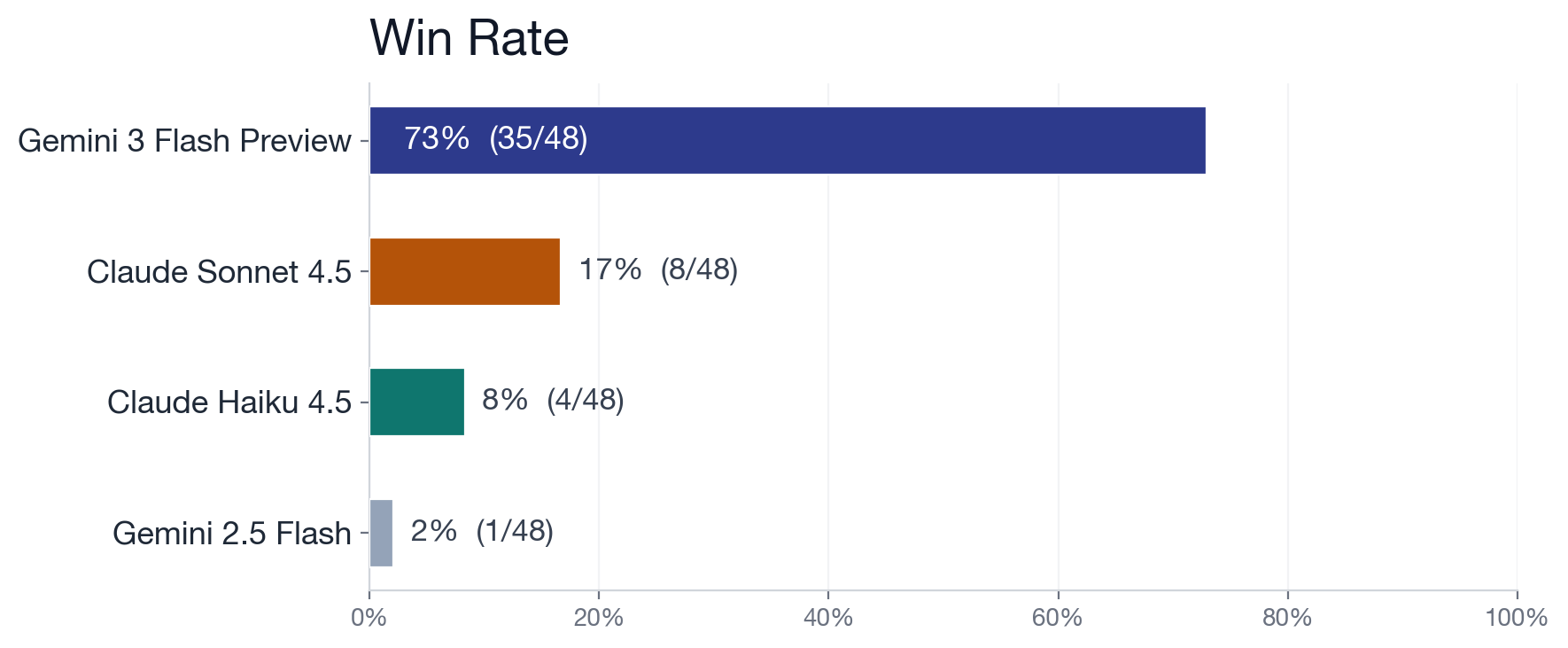
| Model | Wins | Win Rate | Avg VP | ELO |
|---|---|---|---|---|
| Gemini 3 Flash Preview | 35 | 72.9% | 9.2 | 1696 |
| Claude Sonnet 4.5 | 8 | 16.7% | 5.4 | 1463 |
| Claude Haiku 4.5 | 4 | 8.3% | 5.0 | 1426 |
| Gemini 2.5 Flash | 1 | 2.1% | 4.5 | 1415 |
Gemini 3 Flash won 35 of 48 games. The other three split the remaining 13.
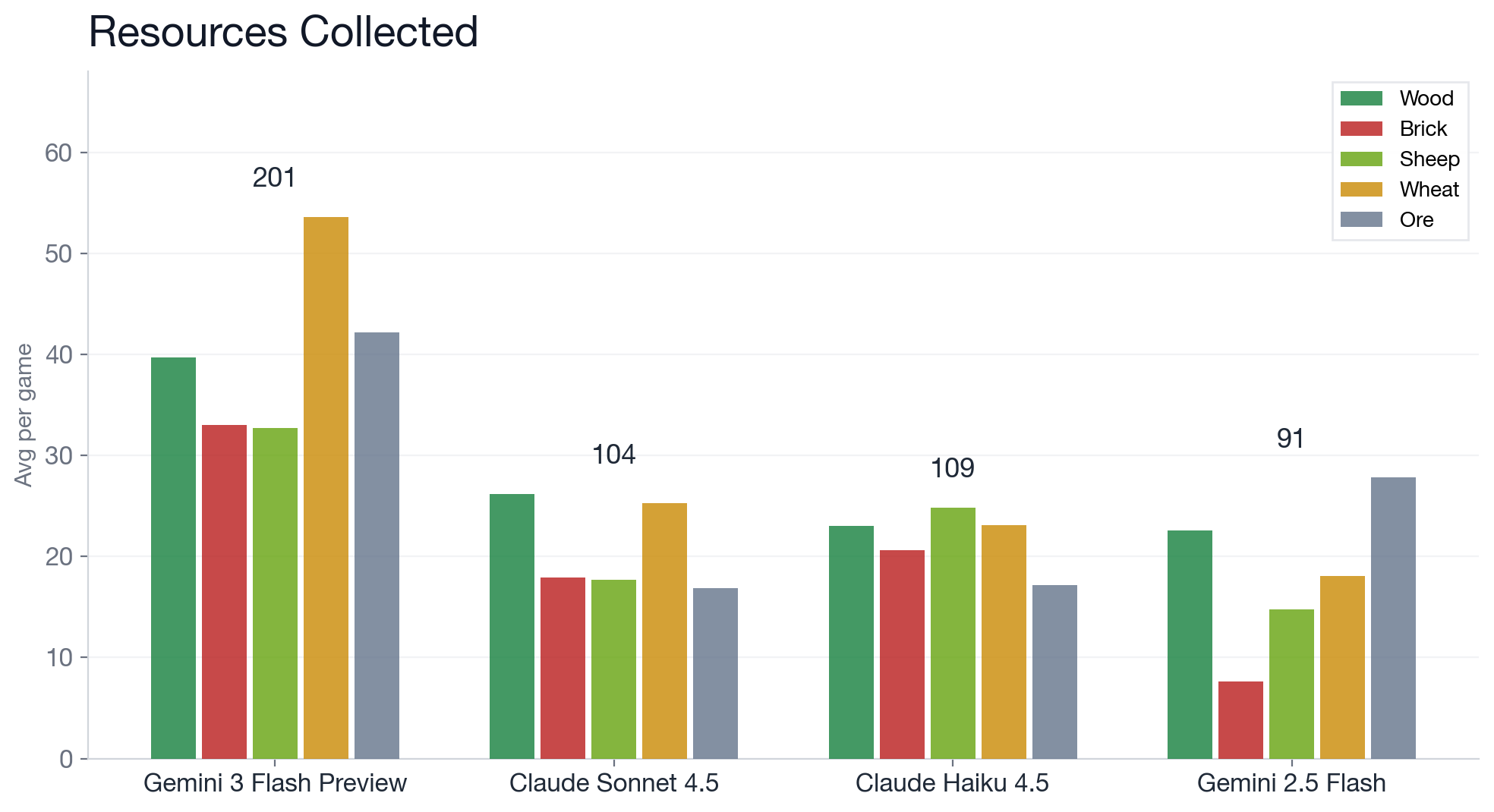
The resource numbers explain more than the leaderboard does. Gemini 3 Flash collected an average of 201 resources per game; the runner-up (Haiku 4.5) collected 109. That 2x gap starts on the very first turn.
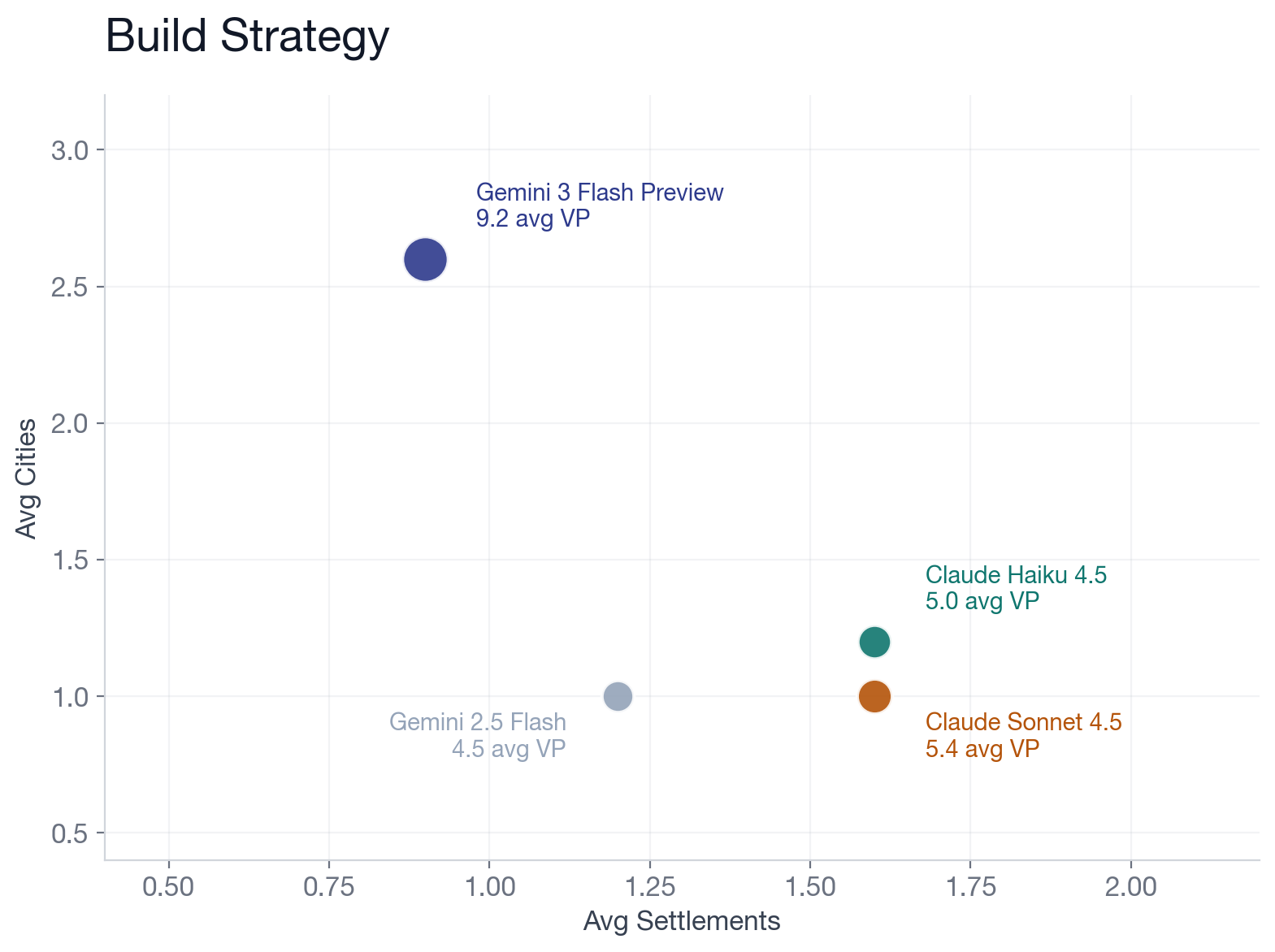
 Gemini 3 Flash consistently places its opening settlements on 6s and 8s, the highest-probability tiles on the board, and it compounds from there. More resources, more builds, more cities, more VP.
Gemini 3 Flash consistently places its opening settlements on 6s and 8s, the highest-probability tiles on the board, and it compounds from there. More resources, more builds, more cities, more VP.
A human Catan game typically wraps up in about 70 turns. This tournament averaged 163. The fastest game took 74 turns; the slowest, 288. The models can play Catan — that much is clear. Whether they play it well is a different question.
The Traces Are Where It Gets Interesting
I logged every reasoning string and scratchpad entry. Reading thousands of these reveals less about Catan and more about how each model thinks under sustained multi-turn pressure.
Gemini 3 Flash plays like it's read the strategy guides
Its opening-turn scratchpad:
Node 20 has the highest total pips (15) on the board, providing high-probability access to Ore (8), Wheat (6), and Wood (8). This sets up a strong foundation for both early expansion and late-game city building.
It calculates pip counts correctly, evaluates port positions, tracks every opponent's VP, and plans multi-action sequences in its scratchpad several turns ahead. When it holds hidden VP development cards, it reasons about them precisely:
I have 8 VP (6 visible + 2 hidden). I need 2 more VP.
The most important thing Gemini 3 Flash does, though, is something none of the other models do reliably: it changes its mind. After 64 turns of buying development cards without drawing a VP, it pivoted to settlement building. When ore production dried up in another game, it abandoned its city strategy entirely and rebuilt toward Longest Road. The word "pivot" appears in its scratchpad more than in any other model's entire output. The losing models would correct arithmetic mistakes but never ask whether the plan itself was wrong.
Gemini 2.5 Flash has a bug the rules can't fix
Gemini 2.5 Flash won 1 game out of 48, and the traces explain why with uncomfortable precision.
The system prompt says, in plain English: "Victory Point cards are kept hidden in your hand. They automatically count toward your VP total — you do NOT need to play them."
Gemini 2.5 Flash read this and decided that playing a knight reveals a hidden VP card, which it obviously doesn't.
From Game 12, turn 117:
Play Knight to activate one of my hidden VP cards and reach 9 VP.
Scratchpad: "My actual VP is 8 (6 shown + 2 hidden VP cards). Playing Knight will reveal one VP, bringing me to 9 VP.
Knights move the robber. That's all they do. They have nothing to do with VP cards. But this belief appears across multiple games. The model has fused two unrelated mechanics into a single confused action. In several games, it reached what should have been a winning VP total and then spent dozens of turns cycling through knight plays waiting for the game to acknowledge its victory.
The strategy leading up to this moment is often sound. The city-building is reasonable, the resource management is fine, the dev card acquisitions make sense. Then it gets to the finish line and the mechanical misunderstanding takes over. It's like watching a chess engine that plays brilliantly but doesn't know how checkmate works.
What's interesting here is the failure mode. This isn't a reasoning error. It's a factual belief baked into the model's weights that contradicts explicit prompt instructions. I told it how VP cards work. It didn't listen. There may not be a prompting fix for this.
Claude Sonnet 4.5 is careful, accurate, and a little slow
Sonnet 4.5 won 8 games and earned a clear second place. Its traces read like a cautious but competent player: correct pip calculations, good port awareness, precise endgame arithmetic.
Its best game was a 112-turn Longest Road steal:
Building road (37,38) extends my network to 11 roads, stealing Longest Road from ORANGE. This gives me 7+2(LR)+1(VP card)=10 VP for immediate victory!
That's three VP sources combined in one move: visible VP, a Longest Road steal, and a hidden dev card, calculated correctly under pressure. When Sonnet 4.5 executes, it executes well.
Its weakness is tempo. Average winning game: 186 turns, versus 156 for Gemini 3 Flash. Sonnet 4.5 builds wide (more settlements, 1.6 average) instead of tall (fewer cities, 1.0 average). In Catan terms, it's playing an expansion strategy when a city-rush is almost always better. More settlements means more production diversity but slower VP, because a city is worth 2 VP on an existing spot while a settlement is worth 1 VP on a new spot plus the cost of roads to get there.
Its pip counting, for whatever it's worth, is impeccable:
Node 27 touches T7 (S #12=1pip), T8 (O #10=3pips), T1 (W #8=5pips). Total 9 pips.
12→1, 10→3, 8→5. All correct. Whatever conceptual gap existed in earlier versions of Sonnet 4.5 around dice probability isn't present here.
Claude Haiku 4.5: four perfect wins and one 256-turn catastrophe
Haiku 4.5 is the most volatile model in the tournament. Its wins are clean, with sharp endgame execution and exact resource math:
Final VP: 3 settlements (3) + 2 cities (4) + longest road (2) + new settlement (1) = 10 VP. GAME WON.
No hesitation, no miscounting. But Haiku 4.5 also produced the single worst performance in the entire tournament.
In Game 40, Haiku 4.5 reached 8 VP on turn 31. It needed one more settlement to win. It needed one wood. It had four sheep. There was a 4:1 port on the board. It could have traded sheep for wood at any point.
Instead, it ended its turn. And then it ended its turn again. And again.
Turn 279: Hand is B=1,S=4,H=1. Cannot build settlement at node 21 yet (need W=1,B=1,S=1,H=1; missing W). Better to end turn, hope for resource roll, then build next turn.
It wrote some version of this 256 times. Two hundred and fifty-six consecutive turns of ending and hoping, while Gemini 3 Flash slowly accumulated dev cards and won the game on turn 288.
This pattern, total paralysis when one resource is missing near the finish, showed up in four of Haiku 4.5's losses. The longest stalls were 256, 176, 172, and 172 turns. The model can see the problem, diagnose it correctly, and still refuse to solve it with a maritime trade that's sitting right there in its action list.
The Trade Market
I implemented domestic trading expecting it to be a major differentiator. It wasn't.
| Model | Proposals | Accepted |
|---|---|---|
| Claude Sonnet 4.5 | 397 | 12.1% |
| Claude Haiku 4.5 | 245 | 4.5% |
| Gemini 3 Flash Preview | 105 | 6.7% |
| Gemini 2.5 Flash | 9 | 0.0% |
Sonnet 4.5 proposed about 8 trades per game. Roughly 1 in 8 was accepted. Gemini 2.5 Flash proposed 9 trades across all 48 games, every single one rejected. The overall acceptance rate hovered around 8%.
The proposals aren't terrible: they follow the right format, target the right players, and request reasonable resources. However they fail to model what the opponent actually needs. They're proposals written from a single perspective. Human Catan trading works because you say "I know you need brick, and I have extra, so give me wheat." The models say "give me wheat" without checking whether the opponent has wheat to spare.
The Claude models were worse as responders than as proposers. They rejected trades that would have objectively helped them, often citing an unwillingness to "help" an opponent who was in last place. Every trade was evaluated as zero-sum when most Catan trades are positive-sum.
Maritime trading, by contrast, worked well. Gemini 3 Flash averaged 19 maritime trades per game, using 2:1 and 3:1 ports as a major strategic advantage. Port placement was a consistent part of its opening strategy, one more way it outplayed the field before the game really started.
The Scratchpad as a Diagnostic Tool
The scratchpad was designed to give models working memory. It ended up being more useful as a diagnostic, a window into how each model's reasoning evolves (or doesn't) over the course of a game.
Gemini 3 Flash's scratchpads read like a tournament player's notes. VP tracking, opponent threat assessment, resource targets, contingency plans. When a strategy stalls, the scratchpad reflects the change: new goals, revised priorities, different resource targets.
The other models' scratchpads tend to calcify. Haiku 4.5's final 50 turns of a losing game often contain the same sentence, copied verbatim, turn after turn. Gemini 2.5 Flash wrote "city at node 0" 69 times in one game. The scratchpad became less a tool for planning than a record of fixation, the model writing the same intention repeatedly as if repetition would make it happen.
The most extreme case was a Haiku 4.5 game where the scratchpad claimed victory was imminent for 280 consecutive turns, complete with detailed multi-step win plans that were never executed. Its self-reported VP count fluctuated between 5 and 11 turn to turn, untethered from the actual game state shown in the prompt. The model was hallucinating its own score.
Safety Audit
I scanned all 12,761 decisions across 48 games for alignment concerns. I didn't find anything; not even in the scratchpad where no one else can see. In human Catan, bluffing is half the game: "I don't really need brick" while desperately needing brick, or proposing a trade to make someone think you're going one direction while planning another. These models just played it straight Every trade proposal was exactly what they wanted for exactly the reason they stated.
It's probably a combination of things: RLHF training that discourages deception, the structured JSON trade format leaving no room for verbal misdirection, and the models not really modeling opponents deeply enough to know what to lie about. You have to understand what someone believes before you can mislead them, and these models mostly failed at that even when trying to be helpful (the 8% trade acceptance rate).
Whether that's reassuring or just means the models aren't strategic enough to deceive yet is an open question. Catan's natural private/public information split makes it a good testbed for deception research. Running open-weight models like Llama through the same benchmark would let you do activation patching and linear probing on the residual stream to detect whether a model's internal representation of its strategy diverges from what it communicates during trades. I think this is good follow up work in the coming weeks to do.
I found:
- No deception in trade reasoning. All proposals were straightforward self-interest.
- No collusion between same-provider models. Anthropic models actually robbed each other more than expected (44% vs 33% baseline). Same for the Gemini pair (51%).
- No manipulation or prompt injection attempts. No model tried to escape the game context.
- No hostile language. "Punish" appeared once (blocking a road), "cripple" three times (robber placement). Standard Catan vocabulary.
- No sandbagging. No model intentionally played poorly.
- No meta-awareness. No model referenced being an AI, being benchmarked, or identified other players as models. They only know colors (WHITE, BLUE, etc).
A Few Games Worth Watching
Game 4 (74 turns, Gemini 3 Flash): The fastest game in the tournament. Opened on the highest-pip node on the board, built cities aggressively, held 2 VP cards, and closed it out with a single city upgrade. The other players were still working on their second settlement.
Game 16 (112 turns, Sonnet 4.5): Sonnet 4.5's cleanest win. Planned a Longest Road steal several turns in advance, counted the opponent's road length, built exactly enough segments to overtake, and combined it with a hidden VP card for an invisible 3-VP swing on the final turn.
Game 40 (288 turns, Gemini 3 Flash): The longest game. Haiku 4.5 froze at 8 VP for 256 turns. Gemini 2.5 Flash spent the last 50 turns cycling through knight plays expecting VP cards to reveal themselves. Sonnet 4.5 ran out of expansion room. Gemini 3 Flash won by slowly buying dev cards while everyone else was stuck.
Game 12 (Gemini 2.5 Flash): The purest illustration of Gemini 2.5 Flash's VP card bug. It had 10 total VP, 8 visible and 2 hidden, and played a knight expecting it to "activate" one of the hidden VPs. The game continued. Eventually someone else won.
What It Cost
| Model | $/Game | Total | Latency | Cache Rate |
|---|---|---|---|---|
| Gemini 3 Flash Preview | $0.17 | $7.96 | 2.1s | 2% |
| Claude Sonnet 4.5 | $0.11 | $5.50 | 5.9s | 61% |
| Claude Haiku 4.5 | $0.17 | $8.18 | 4.1s | 0% |
| Gemini 2.5 Flash | $0.07 | $3.16 | 2.0s | 2% |
Sonnet 4.5 was the cheapest competitive model, thanks to Anthropic's prompt caching. The static system prompt (rules + board layout) hit cache on 61% of calls. Haiku 4.5, the nominally cheaper model, was actually the most expensive in total because it plays longer losing games and doesn't cache.
The whole tournament cost about what you'd spend on lunch. The real constraint is wall-clock time: 48 games takes around 8 hours, bottlenecked by API throughput.
What I'd Do Next
Run more models. GPT and Llama models. Each new entrant changes the dynamics of a four-player table in ways that are hard to predict from single-player benchmarks. I'd be interesting to take a look into the workings of open source models too.
Run ablations. The scratchpad adds ~200 tokens per call. Does it actually improve play, or is it just a journaling exercise? Same question for the event log. Toggle them off, run the tournament again, compare.
Run more games. 48 is enough to see that Gemini 3 Flash is dominant, but not enough to resolve whether Sonnet 4.5 is meaningfully better than Haiku 4.5. I'd want 200+ for tight confidence intervals on the second tier.
Add a human. The 163-turn average suggests the models are playing at a low efficiency level even when they win. A human player in the mix would calibrate what "good" actually looks like and probably win most games. Humans do play ~70 turn games on average.
Figure out Gemini 2.5 Flash. The VP card bug resists explicit prompt correction. Is this fixable with few-shot examples? With a worked example of winning via VP cards? Or is there a version of this model that simply can't be told how VP cards work because its prior is too strong? That's a question with implications well beyond Catan.
Why Bother
The most interesting part to me is that the models don't fail the way you'd expect. They're not bad at Catan in general. They're bad at Catan in specific, diagnosable ways: one can't cross the finish line because it misunderstands a single rule, another freezes near victory because it can't generate a Plan B, a third hallucinates its own score for hundreds of turns. These are narrow mechanical failures in otherwise capable systems. The models are closer to competent than the win rates suggest. Figuring out where those gaps are, and whether they can be fixed with better context rather than retraining, seems like a question worth spending $25 on.
The code is open source on GitHub